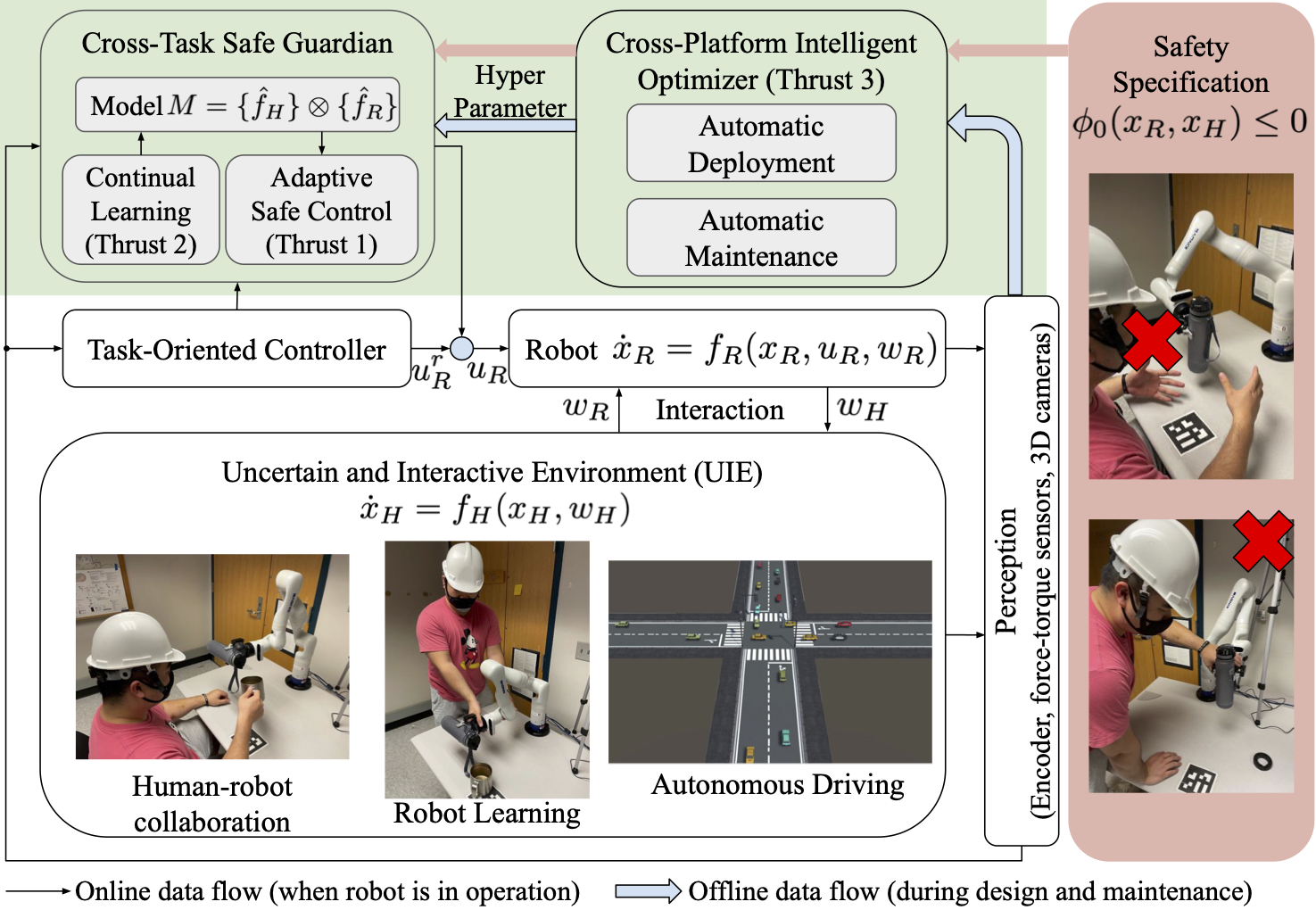
Toward Lifelong Safety of Autonomous Systems in UIE
Overview
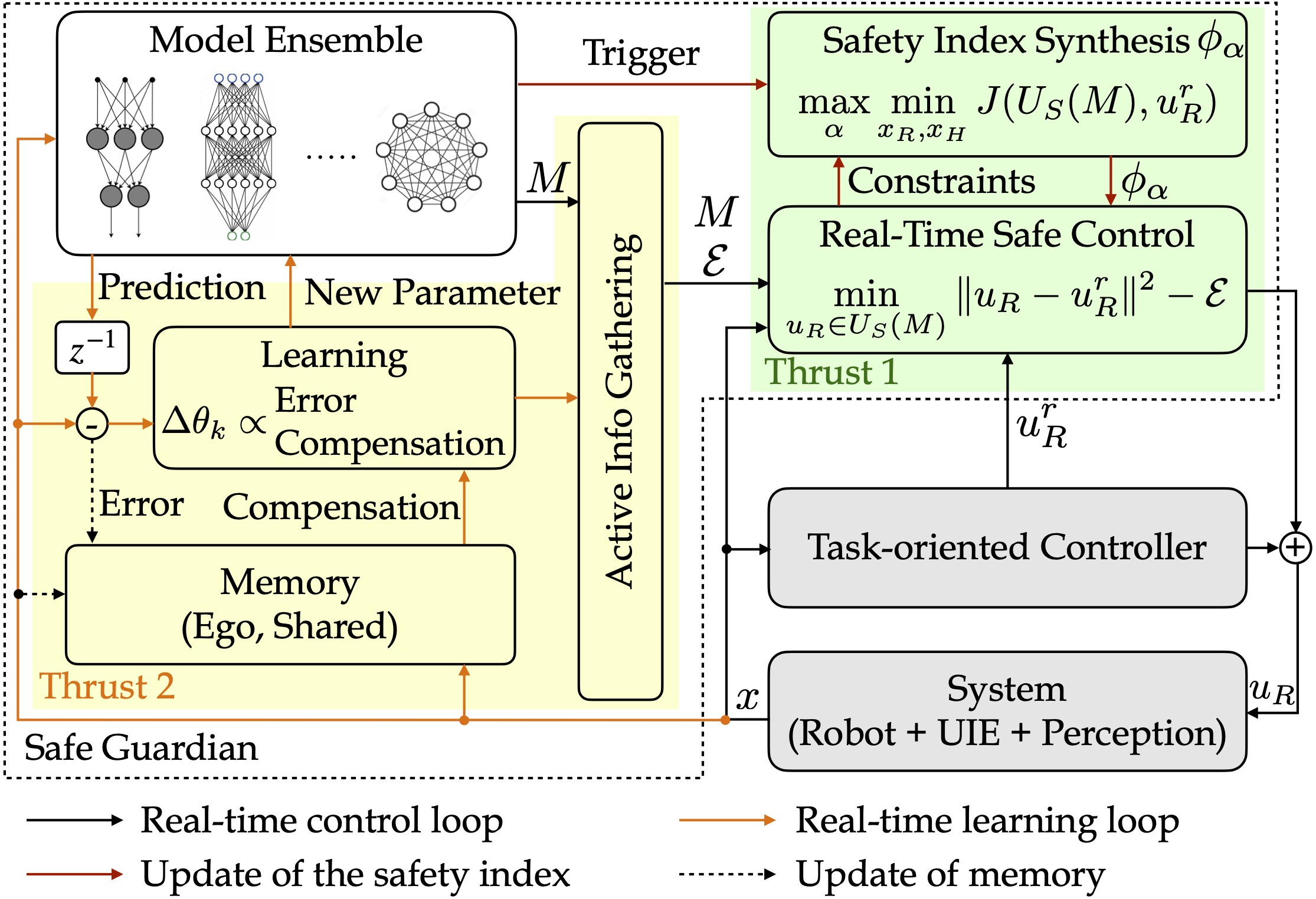
The research objective of this proposal is to study the design principles to achieve optimal lifelong safety of autonomous robotic systems in uncertain and interactive environments (UIEs). For example, this capability will enable industrial collaborative robots to safely and optimally work with unfamiliar human workers in novel tasks throughout the robots’ lifetime. UIEs are the most challenging environments for autonomous systems because they contain other intelligent entities who will react to the ego robot in unknown manners. The safety requirements are represented as constraints on the choices of the autonomous systems to achieve their tasks. Our goal is to optimally augment existing systems (existing hardware platforms with task-oriented controllers) with advanced cross-task safe guardians that will monitor and modify the nominal task-oriented actions. To avoid expensive case-by-case tuning and maintenance, we aim to automate the deployment of the safe guardians and make them self-repairable. The fundamental research question is: how to design and synthesize the safe guardians so that autonomous systems can optimally meet safety constraints throughout their lifetime in UIEs?
Problem Challenges
While existing methods are able to guarantee safety given a well-defined system dynamic model, there are several major challenges to deploy safe guardians for systems in UIEs: 1) It is difficult (if not impossible) to fully anticipate what autonomous robots may encounter in their lifetime. 2) Sometimes failures are inevitable (out of the robot’s control) and how to deal with failures still requires extensive study. 3) Existing solutions require extensive manual case-by-case modeling and tuning.
Research Goal
To address challenge I and achieve lifelong safety, we will equip the cross-task safe guardian with the following capabilities: 1) Continual learning to track the time-varying dynamics of the UIEs (thrust 2); 2) Adaptive safe control to adjust the control strategy according to newly learned dynamic models (thrust 1). To address challenges II and III and achieve optimality in lifelong safety, we will equip the safe guardians with a cross-platform intelligent optimizer that can automatically optimize the safe guardians and account for inevitable failures (thrust 3). The optimality refers to: 1) Optimal task performance when safety is assured. 2) Optimal actions before inevitable failures, i.e., minimize impact. 3) Optimal actions after any failure, i.e., never make the same mistake again. The optimizer will enable knowledge sharing for all guardians to learn from others’ successes and mistakes.
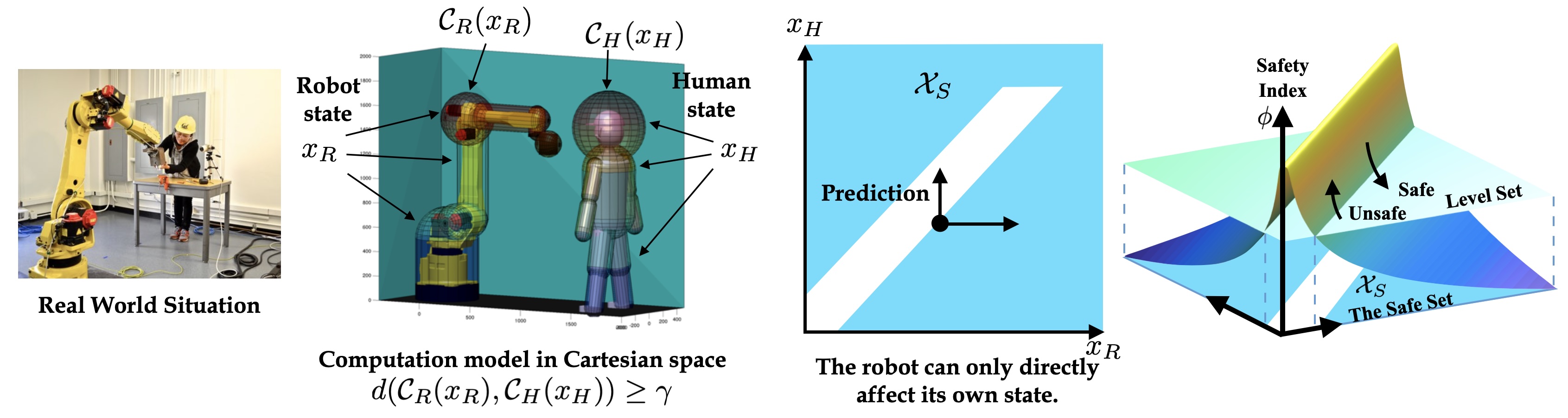
Thrust 1. Safe Control Synthesis
Safe control is synthesized in two steps.
- The first step is similar to “planning,” where we synthesize an energy function $\phi:x\mapsto \mathbb{R}$ given the safety specification $\phi_0$ and the system model $\dot x = f(x,u)$ for $f\in M$, such that:
- The low-energy states are safe, i.e., $\Phi_{\leq 0}:=\lbrace x\mid \phi(x)\leq 0\rbrace \subseteq \lbrace x\mid \phi_0(x) \leq 0\rbrace$.
- There always exists a feasible control input to dissipate the energy, i.e., $U_S(x)$ defined as $\lbrace u_R\in\Omega\mid \dot\phi(x)\leq -\eta(\phi),\forall f\in M\rbrace$ is always $\emptyset$, where $\dot\phi(x)=\nabla_{x}\phi \cdot f$. The set $U_S(x)$ is called the set of safe control, and $\Phi_{\leq 0}$ is called the forward invariant set. The scalar function $\eta:\mathbb{R}\mapsto \mathbb{R}$ is a design parameter, which should be non-decreasing and $\eta(0)\geq 0$.
- The second step is to generate the real-time control signal, where we map the reference control $u^r$ to $U_S(x)$:
1.1 Safety Index Synthesis
We provided an efficient way to parameterize $\phi$ in (Liu & Tomizuka, 2014), setting \(\phi_{\alpha} = \max \lbrace \hat{\phi}_{\alpha},\phi_0 \rbrace\) with $\hat{\phi}_{\alpha} = c+\phi_0^* + k_1\dot \phi_0 + k_2\ddot{\phi}_0 +\ldots + k_n \dot{\phi}_0^{(n)}$, where:
- $c \geq 0$,
- $\phi_0^*(x)\leq 0 \Longleftrightarrow \phi_0(x)\leq 0$,
- and the roots of $1+k_1s+k_2s^2+\cdots k_ns^n=0$ are negative real.
We proved that \(\phi_\alpha\) satisfies the two requirements if \(\alpha = [c,\phi_0^*,n,k_1,\ldots,k_n]\) are properly chosen. Intuitively, the higher-order terms are introduced to ensure that the safety index has a relative degree of one to the robot control, and the term $\phi_0^*$ is introduced to nonlinearly shape the gradient of $\phi$. And both \({\phi}_\alpha\) and \(\hat{\phi}_\alpha\) are called safety indices.
For a typical second-order system, e.g., systems that are controlled through torque or acceleration, we can define \(\hat{\phi}_\alpha = c+d_{min}^n-d^n +k\dot d\) where \(d\) is the smallest relative distance from the ego agent to the obstacle; and \(d_{min}\) is the minimum distance requirement. Then the safety index synthesis problem is essentially figureing out the correct parameters \(c,n,k\) such that \(U_S(x)\) is non-empty, i.e., there alwasy exist a feasible safe control.
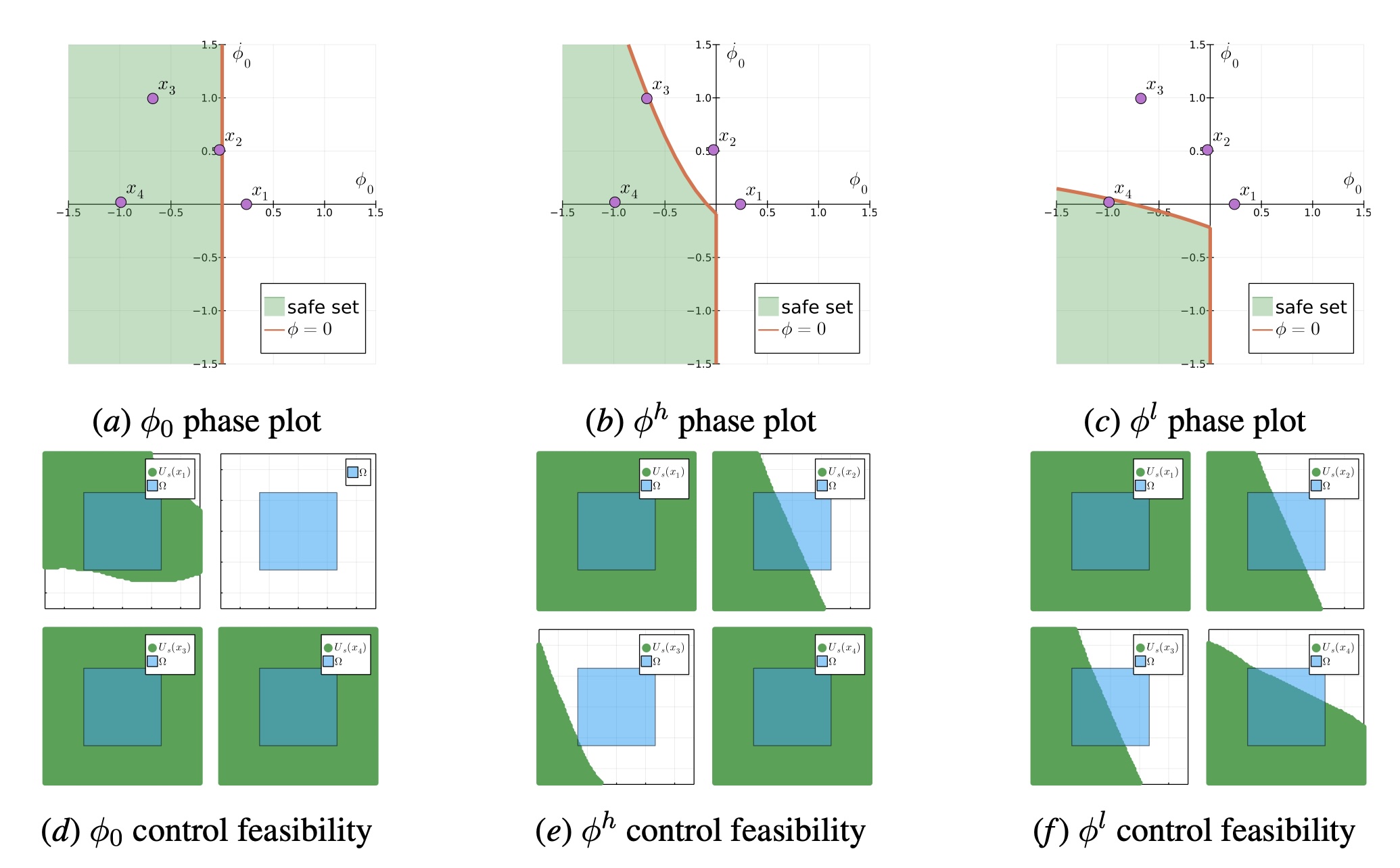
In our prior work (Wei & Liu, 2022), we use evolutionary optimization to find the parameters \(\alpha\). The figure below shows the phase plots and control feasibility plots for three cases, the original safety specification, the hand-tuned safety index, the CMA-ES optimized safety index. The first row shows the phase plot for different safety index. And the second row shows the control spaces at four sampled states x1 to x4. The blue squares denotes the control limit Ω. The green areas are the feasible controls that satisfy the safety constraint. Before the safety index synthesis, there is no feasible control for x2. And for the manually designed safety index φh, there is almost no feasible control for x3. But for the learned safety index, the feasibility is guaranteed for arbitrary states.
In (Ma et al., 2022), we studied joint synthesis of the safety index and the control policy using reinforcement learning.
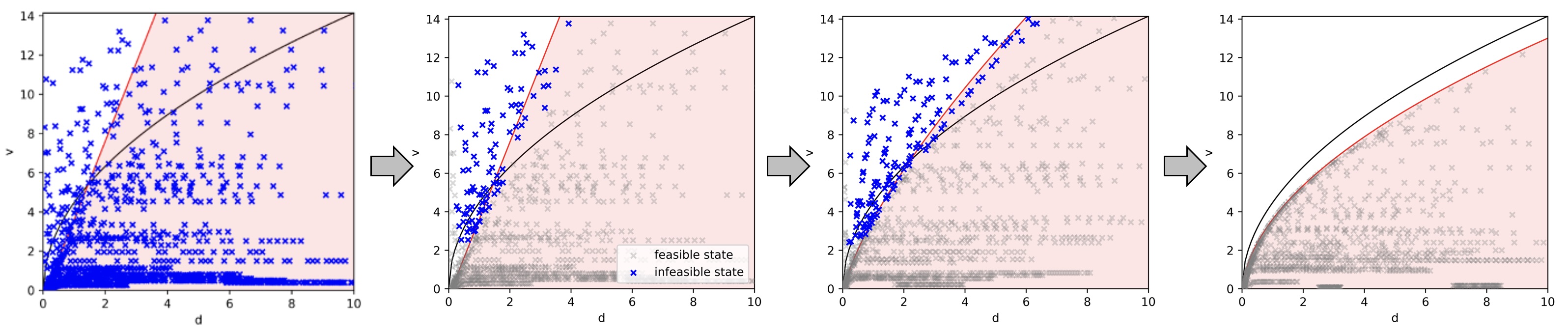
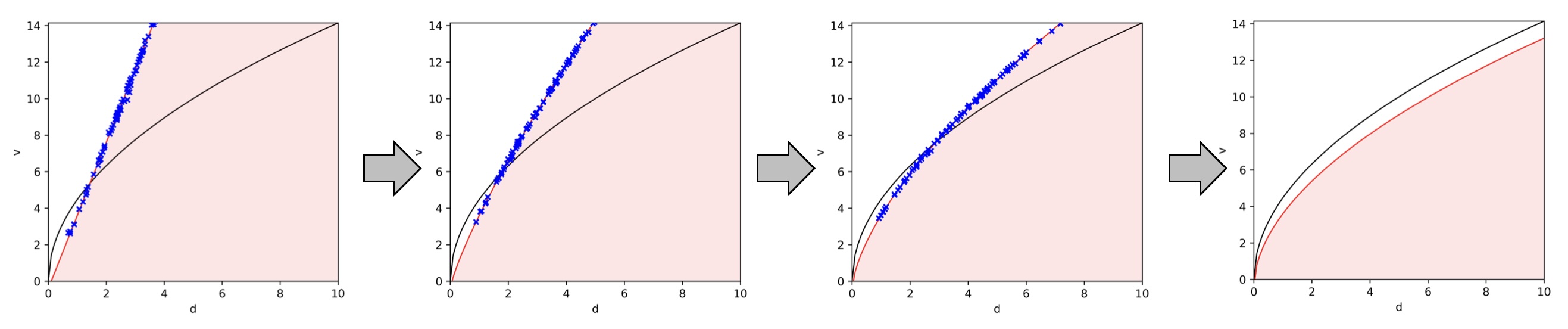
1.1.1 Synthesis with adversarial optimization
In this NSF project, we explored using adversarial optimization to optimize a neural safety index where \(c\) is now a neural network and \(n=1\). The method consists of a learner-critic architecture, in which the critic gives counterexamples of input saturation and the learner optimizes a neural safety index to eliminate those counterexamples. We provide empirical results on a 10D state, 4D input quadcopter-pendulum system. Our learned safety index avoids input saturation and maintains safety over nearly 100% of trials.
-
[C53] Safe Control Under Input Limits with Neural Control Barrier Functions
Simin Liu, Changliu Liu and John Dolan
Conference on Robot Learning, 2022
1.1.2 Synthesis with sum of square programming
Our study shows that ensuring the non-emptiness of safe control on the safe set boundary is equivalent to a local manifold positiveness problem, and this problem is equivalent to sum-of-squares programming via the Positivstellensatz of algebraic geometry. In this way, we can avoid sampling during the safety index synthesis, and provide stronger formal guarantees. We developed a series of methods that leverages sum-of-squares programming to find the hyperparameters of the safety index regarding both offline synthesis and online adaptation.
-
[C56] Safety index synthesis via sum-of-squares programming
Weiye Zhao, Tairan He, Tianhao Wei, Simin Liu and Changliu Liu
American Control Conference, 2023
-
[C67] Safety Index Synthesis with State-dependent Control Space
Rui Chen, Weiye Zhao and Changliu Liu
American Control Conference, 2024
-
[C70] Real-time Safety Index Adaptation for Parameter-varying Systems via Determinant Gradient Ascend
Rui Chen, Weiye Zhao, Ruixuan Liu, Weiyang Zhang and Changliu Liu
American control Conference, 2024
-
[C74] Synthesis and verification of robust-adaptive safe controllers
Simin Liu, Kai S Yun, John M Dolan and Changliu Liu
European Control Conference, 2024
1.1.3 Black-box synthesis
For systems which are hard to explicitly model, based on our prior work on implicit safe set algorithm (Zhao et al., 2021), we developed a comprehensive sampling and synthesis strategy to achieve probabilisitic safety guarantees.
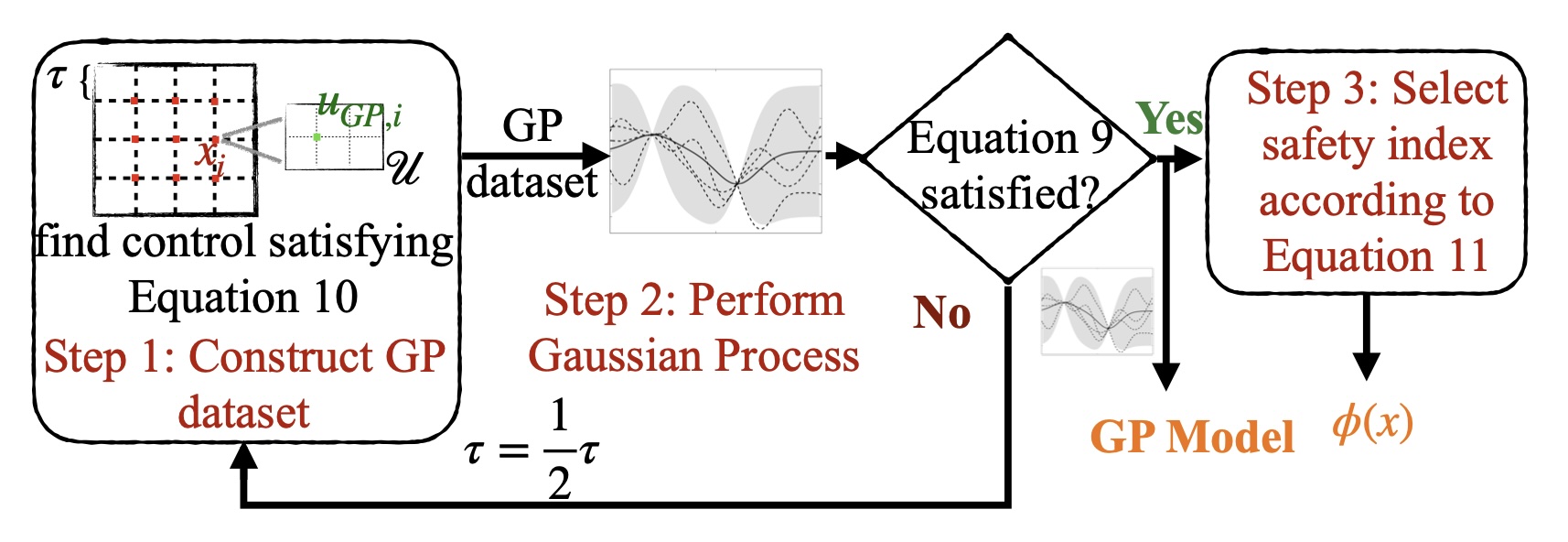
-
[C57] Probabilistic safeguard for reinforcement learning using safety index guided gaussian process models
Weiye Zhao, Tairan He and Changliu Liu
Learning for Dynamics and Control Conference, 2023
1.1.4 Formal synthesis and verification
To address potential approximation errors inherent in safety index synthesis using data-driven approaches, we introduced the a scalable formal synthesis and verification method for neural safety functions.
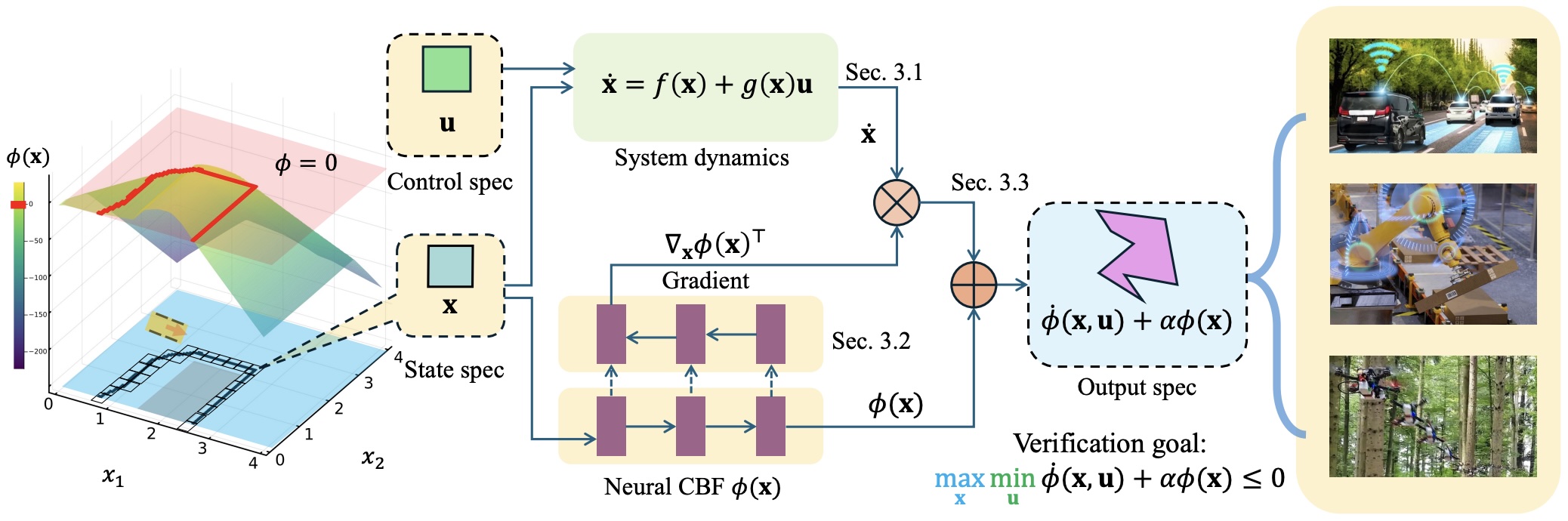
-
[C81] Verification of Neural Control Barrier Functions with Symbolic Derivative Bounds Propagation
Hanjiang Hu, Yujie Yang, Tianhao Wei and Changliu Liu
Conference on Robot Learning, 2024
1.2 Robust Safe Control During Execution
This line of research answers the following question: how can we do the projection from $u^r$ to $U_S(x)$ efficiently, especially when $U_S(x)$ is nonlinear (which typically happens when there are uncertainties in models)?
1.2.1 Non-conservative robust safe control
Model mismatches prevail in real-world applications. Ensuring safety for systems with uncertain dynamic
models is critical. To overcome the loose over-approximation of uncertainties in prior works, we
propose a control-limits aware robust safe control framework for bounded state-dependent uncertainties, leveraging Convex Semi-Infinite Programming, which is the tightest formulation for convex bounded uncertainties and leads to the least conservative control.
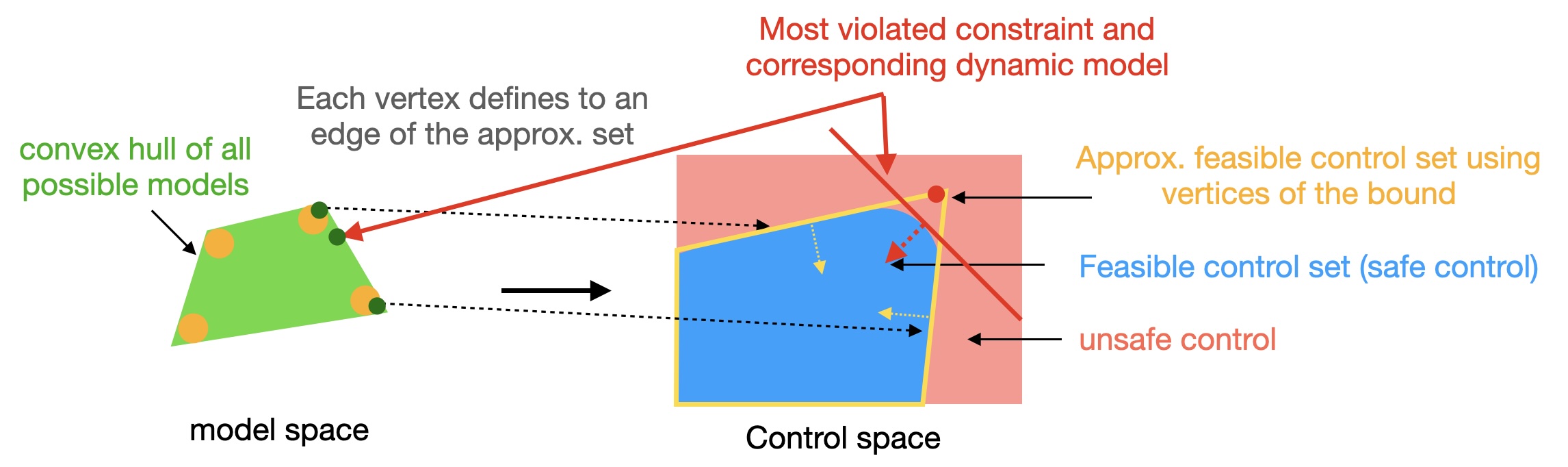
-
[J15] Persistently feasible robust safe control by safety index synthesis and convex semi-infinite programming
Tianhao Wei, Shucheng Kang, Weiye Zhao and Changliu Liu
IEEE Control Systems Letters, 2022
1.2.2 Multi-modal safe control
Existing robust safe controllers, designed primarily for uni-modal uncertainties, may be either overly conservative or unsafe when handling multi-modal uncertainties. To address the problem, we introduce a novel framework for robust safe control, tailored to accommodate multi-modal Gaussian dynamics uncertainties and control limits.
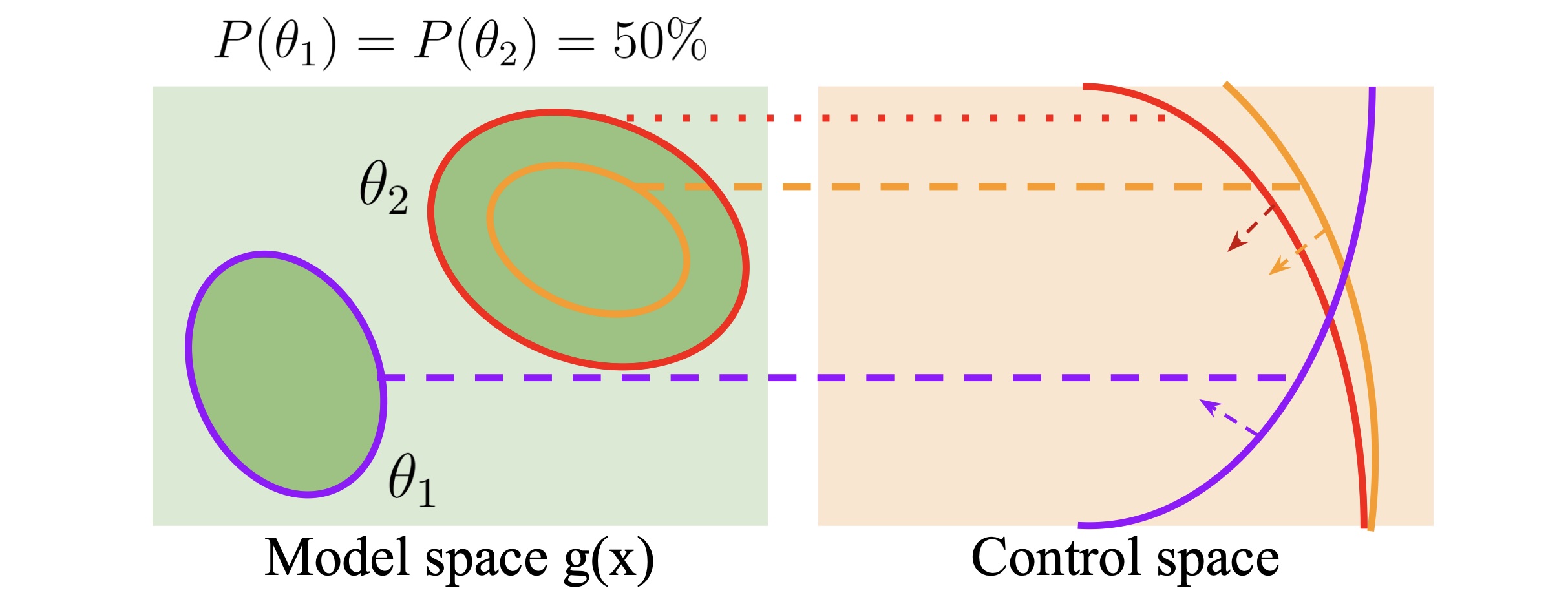
-
[C66] Multimodal Safe Control for Human-Robot Interaction
Ravi Pandya, Tianhao Wei and Changliu Liu
American Control Conference, 2024
-
[U] Robust Safe Control with Multi-Modal Uncertainty
Tianhao Wei, Liqian Ma, Ravi Pandya and Changliu Liu
arXiv:2309.16830, 2023
1.2.3 Zero-shot transfer
Considering the fact that there are redundant dynamics in high dimensional systems with respect to the safety specifications, to improve efficiency of control synthesis, we developed a novel approach called abstract safe control. The system abstraction method enables the design of safety index on a low-dimensional model. The resulting safe controller can be directly transferred to other systems with the same abstraction, e.g., when a robot arm holds different tools.

-
[C63] Zero-shot Transferable and Persistently Feasible Safe Control for High Dimensional Systems by Consistent Abstraction
Tianhao Wei, Shucheng Kang, Ruixuan Liu and Changliu Liu
IEEE Conference on Decision and Control, 2023
1.2.4 Computationally efficient safe control over NNDM
Safe control of neural network dynamic models (NNDMs) is important to robotics and many applications. However, it remains challenging to compute an optimal safe control in real time for NNDM. To enable real-time computation, we developed methods to use sound approximations of the NNDM for real-time control.
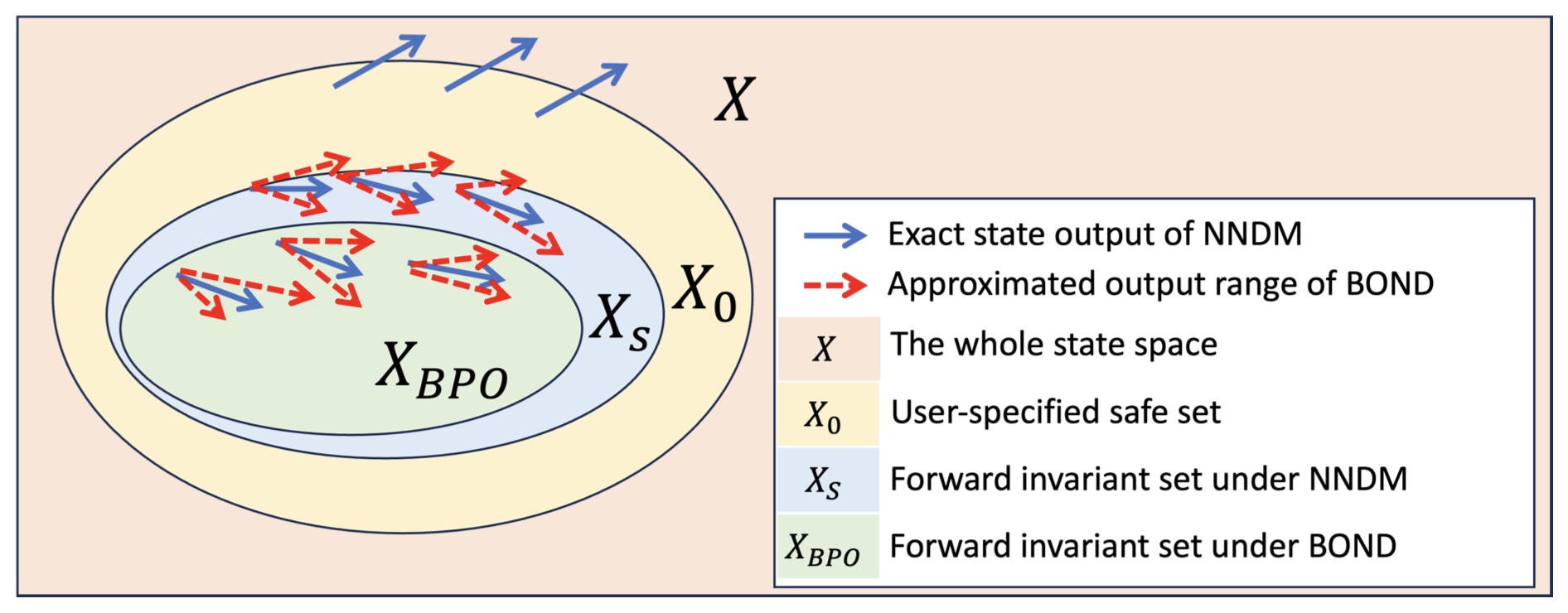
-
[C75] Real-Time Safe Control of Neural Network Dynamic Models with Sound Approximation
Hanjiang Hu, Jianglin Lan and Changliu Liu
Learning for Dynamics and Control Conference, 2024
Thrust 2. Continual Adaptation
This thrust aims to investigate data-efficient methods to continually update the model $M$ to improve closed-loop safety under time-varying dynamics (e.g., minimizing uncertainty in $M$ and enlarging the forward invariant set $\Phi_{\leq 0}$). For a model $\hat f$ parameterized by $\theta$, the continual learning at time $t$ solves the following optimization:
\[{\theta}_t = \arg\min_{\theta} \int_{\tau = 0}^{t} w_{t,\tau}\ l(\dot x^{\tau}-\hat f^{\theta}(x^{\tau},\ldots)) d\tau.\]The parameter estimate $\theta_t$ minimizes the weighted sum of previous fitting errors (with data $x^\tau$ and loss $l$ for all $\tau$). Our prior works (Cheng et al., 2019) (Abuduweili et al., 2019) (Abuduweili & Liu, 2021) let the weights decay exponentially under the assumption that more recent data is more relevant, i.e., $w_{t,\tau} := \lambda^{t-\tau}$ where $\lambda \in [0,1]$ is the forgetting factor. The optimization is solved recursively using error feedback:
\[\dot\theta_t = \beta_t \cdot \text{feedback}(\nabla_{\theta_{t}}\hat f^{\theta_{t}}, \dot x^{t} - \hat f^{\theta_{t}}(x^{t},\ldots)),\]where $\beta_t$ is the learning rate at time $t$, and the feedback term depends on the gradient of the model and the prediction error. Using this approach on deep neural network-based human models (missing reference) and vehicle models (Si et al., 2019), we empirically showed that time-varying dynamics can be tracked and the ground truth trajectories lie in the set of possible trajectories predicted by $M$ with almost probability one (since unexpected rare events happen in reality). To improve sample efficiency (i.e., tracking with faster convergence and smaller uncertainty), we designed a curriculum learning method (Abuduweili & Liu, 2020) to distinguish hard samples (i.e., error belonging to a certain empirical range) from simple samples and then increase the weights for hard samples. This approach significantly increases the model accuracy (i.e., tracking correctly with smaller uncertainty).
However, the remaining challenges are that existing methods that learn parametric models with scarce data are not always optimal for closed-loop safe control. There is room to further reduce the approximation error.
We aim to investigate safety-driven data-efficient continual learning from two aspects: what to learn from (data) and how to learn (algorithm). In terms of what to learn from, we let the system not only passively receive data but also actively gather information to minimize uncertainty regarding the safety constraint in the future. As for how to learn, we study algorithms to maximize information extraction from existing data, especially those are more safety-critical.
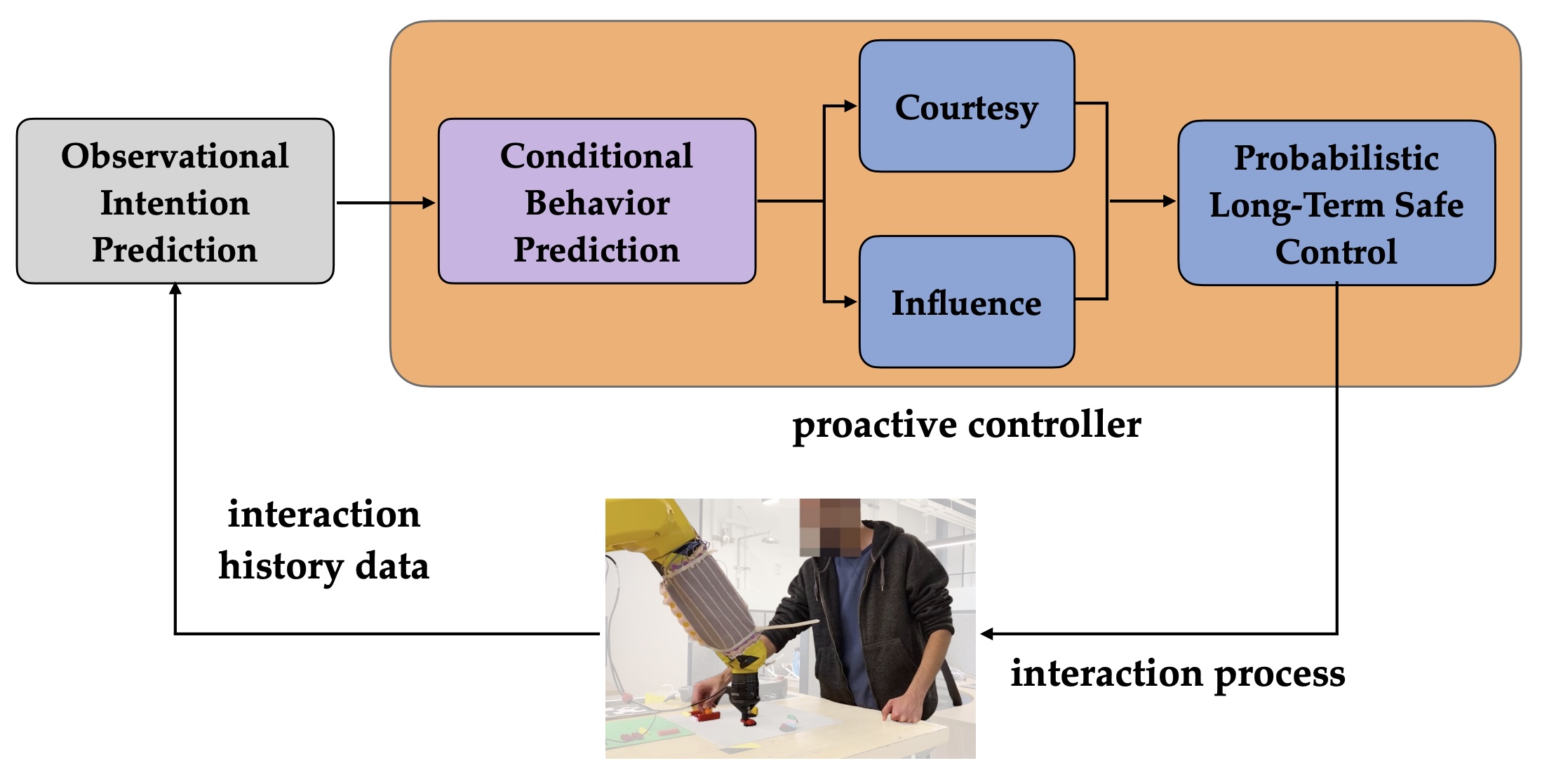
2.1 Safety-Driven Dual Control
Our research in this area aims to balance courtesy and influence in safe control during human-robot interactions and to develop explanations that enhance collaboration efficiency. These works represent significant advancements in proactive and efficient collaboration strategies between humans and robots, particularly in multi-agent settings.
-
[C46] Safe and Efficient Exploration of Human Models During Human-Robot Interaction
Ravi Pandya and Changliu Liu
IEEE/RSJ International Conference on Intelligent Robots and Systems, 2022
-
[C72] Towards Proactive Safe Human-Robot Collaborations via Data-Efficient Conditional Behavior Prediction
Ravi Pandya, Zhuoyuan Wang, Yorie Nakahira and Changliu Liu
IEEE International Conference on Robotics and Automation, 2024
-
[C73] Multi-Agent Strategy Explanations for Human-Robot Collaboration
Ravi Pandya, Michelle Zhao, Changliu Liu, Reid Simmons and Henny Admoni
IEEE International Conference on Robotics and Automation, 2024
2.2 Continual Model Learning
Recognizing the difficulty of learning from scarce and heterogeneous data, we innovatively designed several recalling strategies to enahance model learning.

-
[C65] Online Model Adaptation with Feedforward Compensation
Abulikemu Abuduweili and Changliu Liu
Conference on Robot Learning, 2023
-
[J20] Bioslam: A bioinspired lifelong memory system for general place recognition
Peng Yin, Abulikemu Abuduweili, Shiqi Zhao, Lingyun Xu, Changliu Liu and Sebastian Scherer
IEEE Transactions on Robotics, 2023
Thrust 3. Automatic Deployment
This thrust aims to develop a systematic, automatic, and resource-aware approach to deploy and maintain the safe guardian in various applications. The resource limits include constraints on memory capacity, computation capacity, and communication bandwidth. The deployment requires optimizing the hyperparameters of the system for some performance criterion under resource limits. The maintenance requires handling of the failure cases that are not fully covered during deployment.
3.1 Meta-Control: LLM-Enabled Control Synthesis
We investigated methods to automate the deployment of robot controllers across diverse scenarios by leveraging large language models (LLMs). This effort culminated in the development of Meta-Control, the first LLM-enabled automatic control synthesis approach. Meta-Control leverages LLMs to mimic human reasoning processes, utilizing extensive control knowledge in a structured, systematic manner. This innovative approach, guided by Socratic principles of inquiry, enhances efficiency and scalability in control system design.
-
[C83] Meta-Control: Automatic Model-based Control Synthesis for Heterogeneous Robot Skills
Tianhao Wei, Liqian Ma, Rui Chen, Weiye Zhao and Changliu Liu
Conference on Robot Learning, 2024
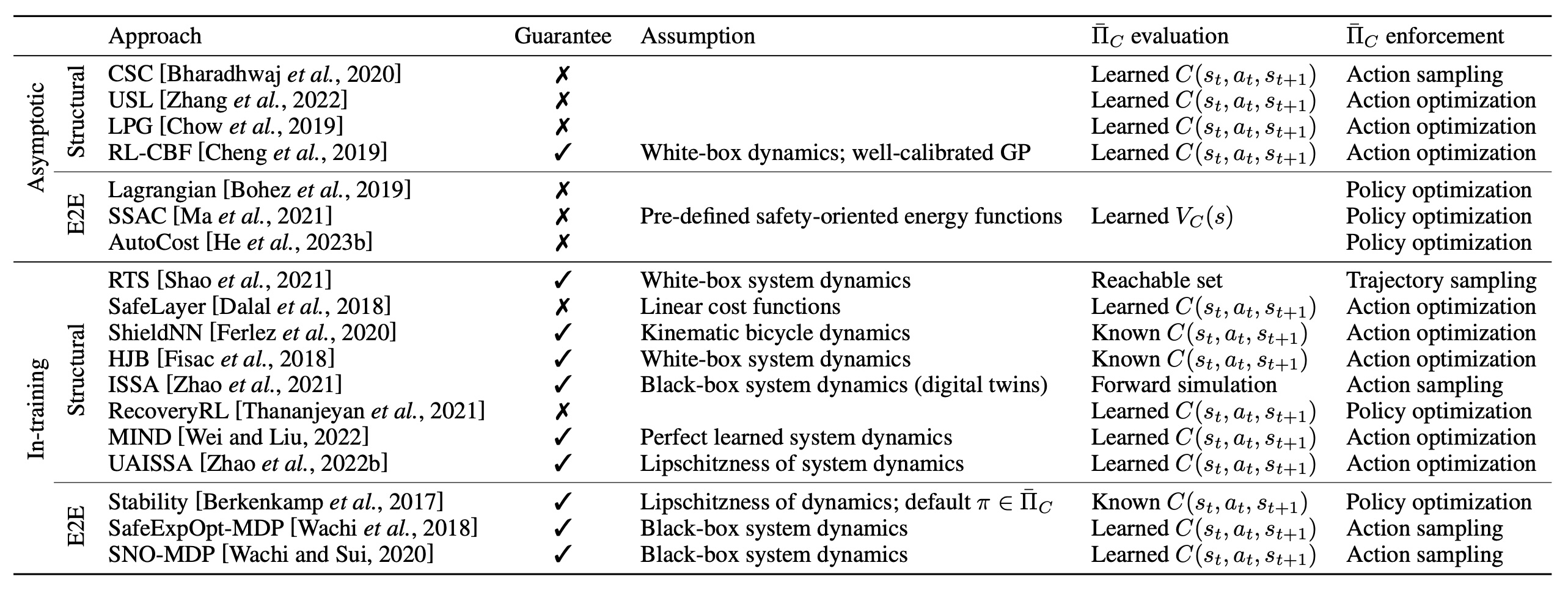
3.2 Safe Policy Learning
This line of work investigated methods for direct safe policy learning.
-
[C60] State-wise safe reinforcement learning: A survey
Weiye Zhao, Tairan He, Rui Chen, Tianhao Wei and Changliu Liu
International Joint Conferences on Artificial Intelligence, 2023
-
[C77] Absolute Policy Optimization: Enhancing Lower Probability Bound of Performance with High Confidence
Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei and Changliu Liu
International Conference on Machine Learning, 2024
Real World Applications
Applications in Robot Arms
-
[J16] A hierarchical long short term safety framework for efficient robot manipulation under uncertainty
Suqin He, Weiye Zhao, Chuxiong Hu, Yu Zhu and Changliu Liu
Robotics and Computer-Integrated Manufacturing, 2023
Applications in Legged Robots
-
[C78] Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion
Tairan He, Chong Zhang, Wenli Xiao, Guanqi He, Changliu Liu and Guanya Shi
Robotics: Science and Systems, 2024
Outstanding Student Paper Award Finalist
Testbed Development and Education
GUARD: Safety Benchmark
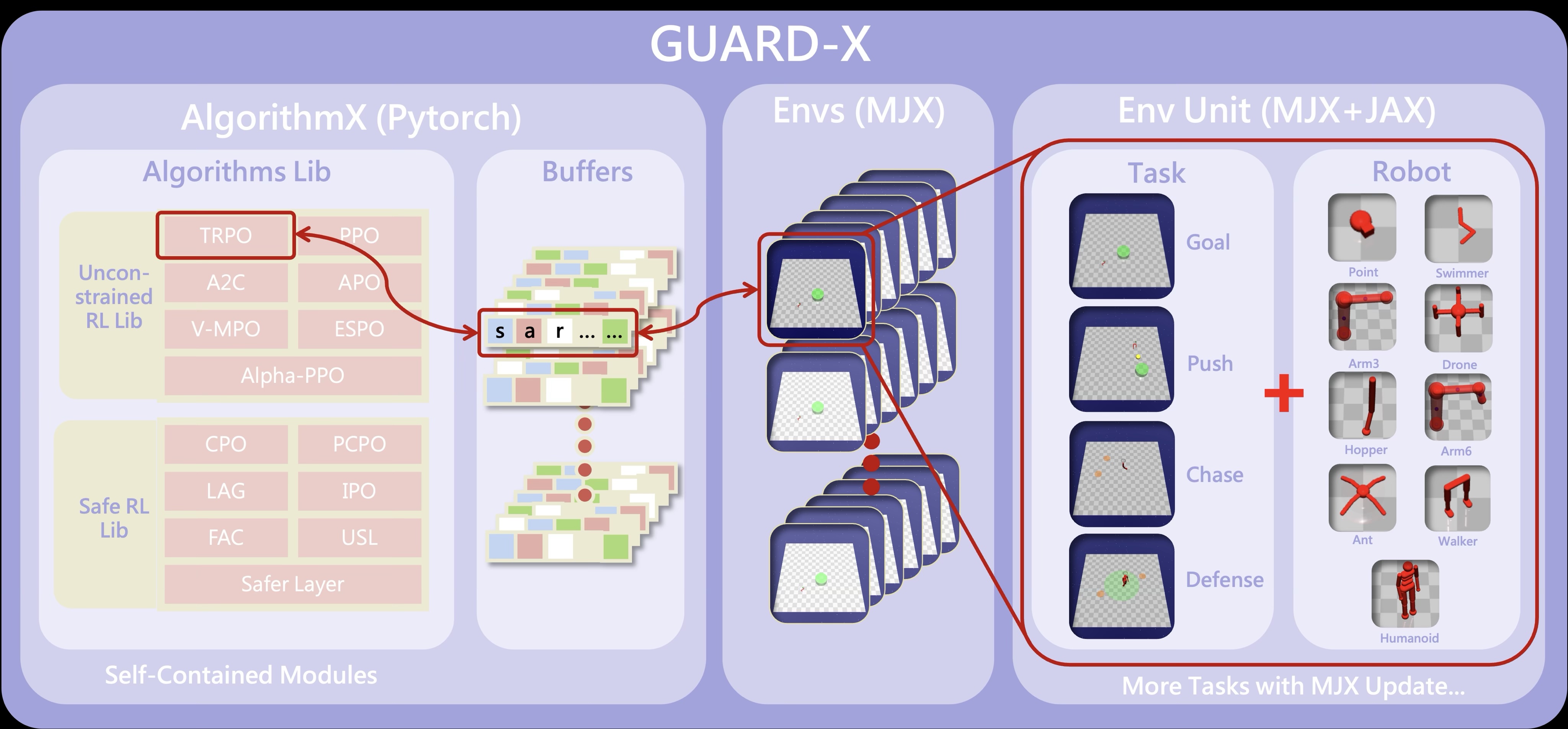
We developed a safety benchmark, GUARD, using the state-of-the-art Mujoco simulator. The benchmark consists of a variety of robots, tasks, safety requirements, and pre-implemented algorithms.
SPARK: Safe Humanoid Toolbox
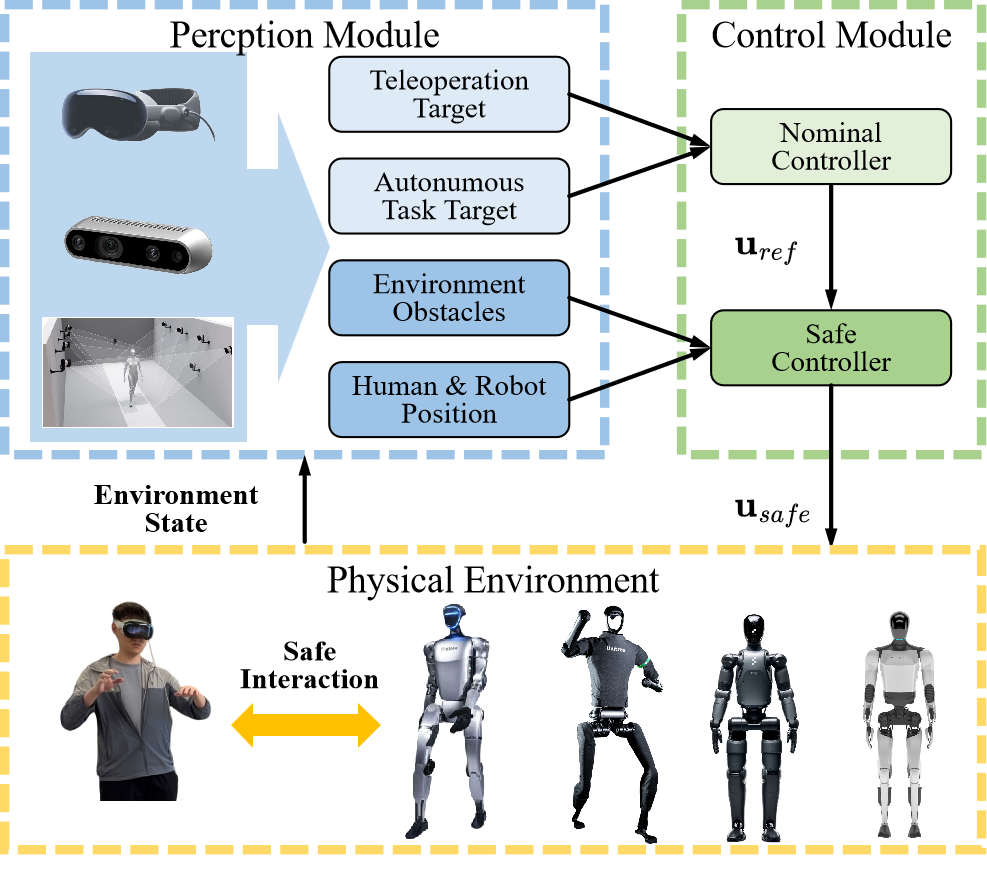
We developed the Safe Protective and Assistive Robot Kit (SPARK), a modular toolbox for ensuring safety in humanoid autonomy and teleoperation. By serving as a fail-safe mechanism, SPARK significantly enhances the safety of existing humanoid systems, advancing the field of safe humanoid robotics. Spark is also integrated into my course 16-883 Provably Safe Robotics.
Associated PhD Thesis
-
[T2] State-wise Safe Learning and Control
Weiye Zhao
PhD Thesis, 2024
-
[T3] Safeguarding and Empowering General Purpose Robots through Abstraction and Constraint Certification
Tianhao Wei
PhD Thesis, 2024
Other Resources
Sponsor: National Science Foundation
Period of Performance: 2022 ~ Now