State-wise Safe and Robust Reinforcement Learning for Continuous Control
Overview:
Robotic safety has been a focal point of research in both the control and learning communities over the past few decades, addressing a wide range of safety constraints from specific, narrow tasks to more general, broad applications. Achieving provable safety guarantees at every time step (state-wise safety or robustness) during a robot’s operation is essential for ensuring both widespread adoption and reliable performance. In real-world settings, algorithms with robust safety measures and theoretical guarantees are critical for the large-scale deployment of robots, as any failure could be irreversible or uncorrectable. For example, autonomous vehicles cannot tolerate even a single malfunction, and collaborative robots must perform efficiently while ensuring the safety of workers. Concurrently, reinforcement learning (RL) has emerged as a powerful tool for enabling superhuman performance, significantly accelerating the acquisition of complex skills. However, the exploratory nature of RL, particularly its trial-and-error approach, complicates the ability to guarantee state-wise performance theoretically. To harness the benefits of superhuman performance in RL while ensuring stability and reliability, we focus on the following key questions:
How can we achieve state-wise performance, or even worst-case state-wise performance, with provable theoretical guarantees?
How can we obtain the strongest possible theoretical guarantees within the stochastic framework of Markov Decision Processes (MDP)?
How can we bridge traditional control methods with RL to acquire robust and safe RL policy without any violations during training?
Research Topics
Safe Reinforcement Learning Benchmark
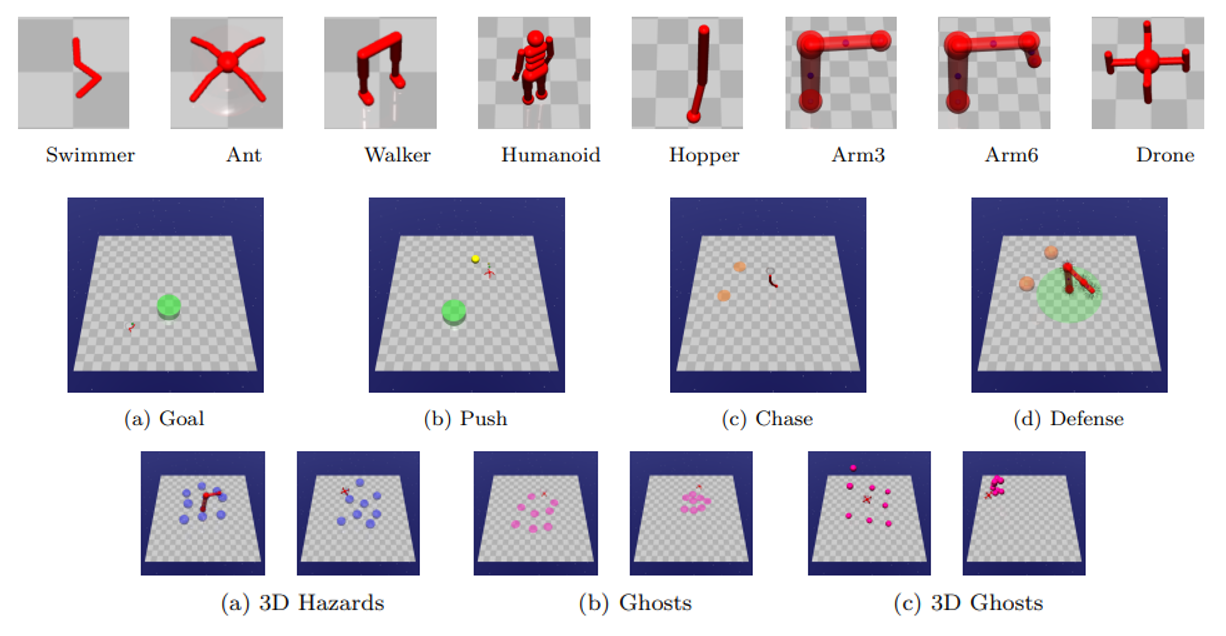
Safe RL, or constrained RL, has emerged as a promising solution, but comparing existing algorithms remains challenging due to the diversity of methods and tasks. This work introduces GUARD, a Generalized Unified SAfe Reinforcement Learning Development Benchmark, filling this gap by offering a generalized, customizable benchmark that includes a wide range of RL agents, tasks, and safety constraints. It also provides comprehensive, self-contained implementations of state-of-the-art safe RL algorithms.
Contributors: Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Ruixuan Liu, Tianhao Wei
Contributors: Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Ruixuan Liu, Tianhao Wei
Publications:
-
[J23] Guard: A safe reinforcement learning benchmark
Weiye Zhao, Rui Chen, Yifan Sun, Ruixuan Liu, Tianhao Wei and Changliu Liu
Transactions on Machine Learning Research, 2024
High-Probability Monotonic Improvement Guarantee for Worst-Case Reward Performance
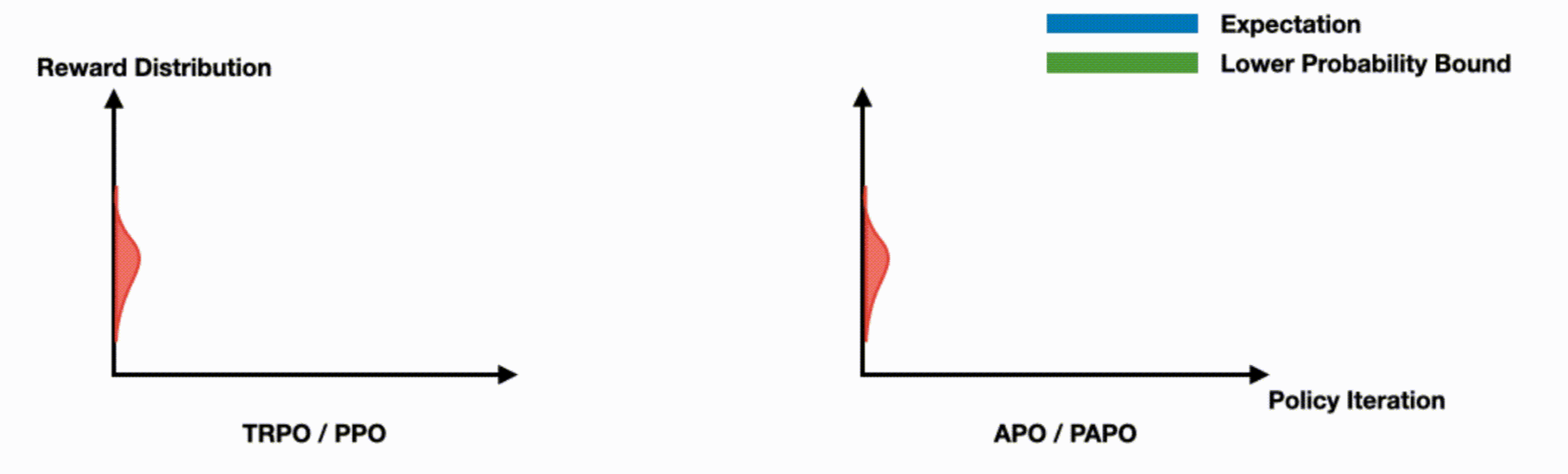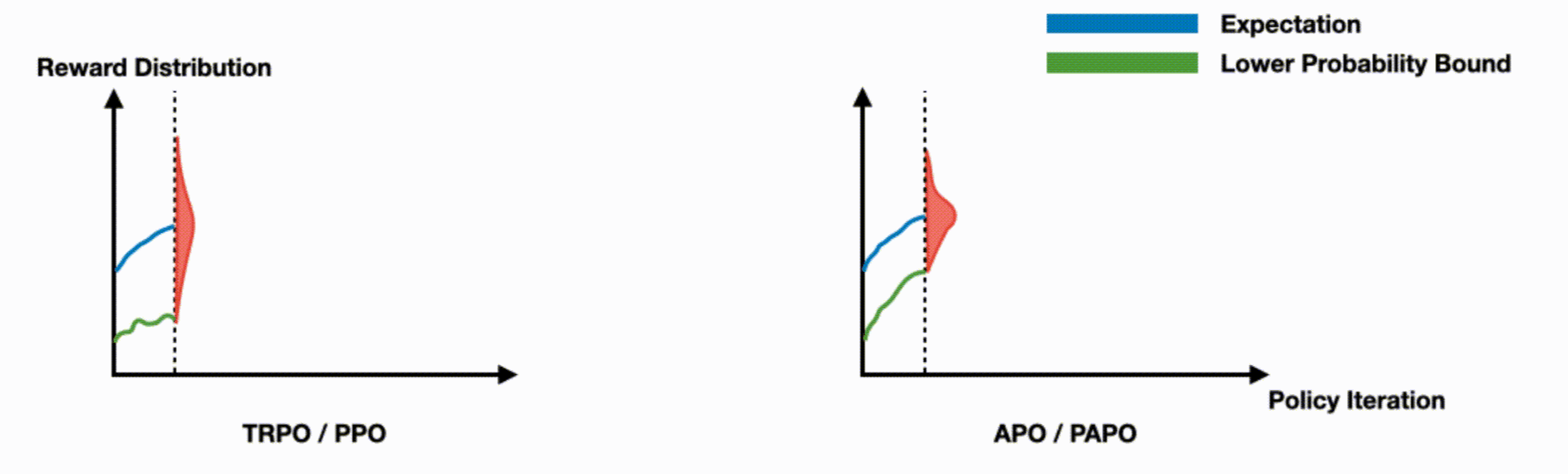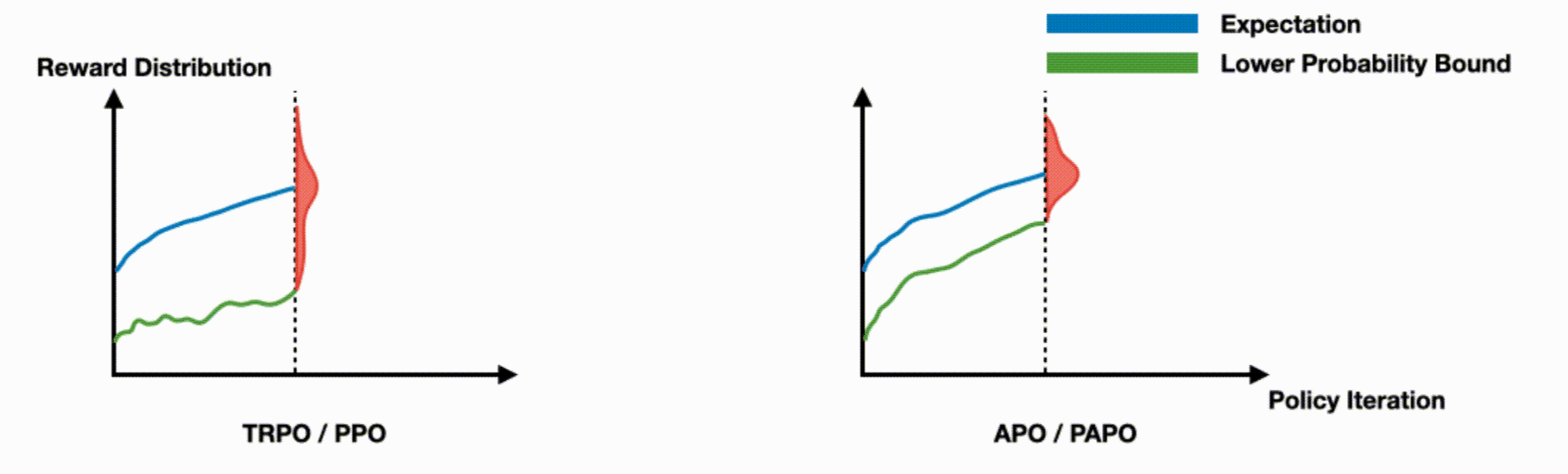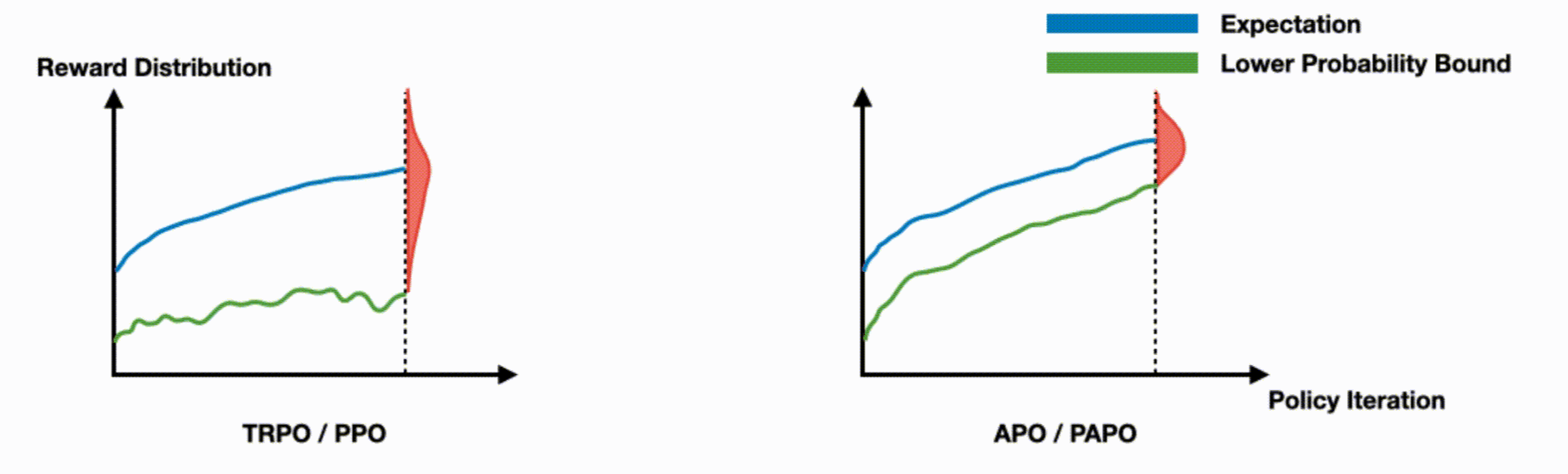
This work tackles a key limitation in trust region on-policy RL algorithms, which focus on expected performance but ignore worst-case outcomes. We introduce a novel objective function that ensures monotonic improvement in the lower probability bound with high confidence. Based on this, we present Absolute Policy Optimization (APO) and Proximal Absolute Policy Optimization (PAPO), which outperform existing methods, achieving significant gains in both worst-case and expected performance.
Contributors: Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei
Contributors: Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei
Publications:
-
[C77] Absolute Policy Optimization: Enhancing Lower Probability Bound of Performance with High Confidence
Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei and Changliu Liu
International Conference on Machine Learning, 2024
High-Probability Satisfication of State-wise Worst-case Safety
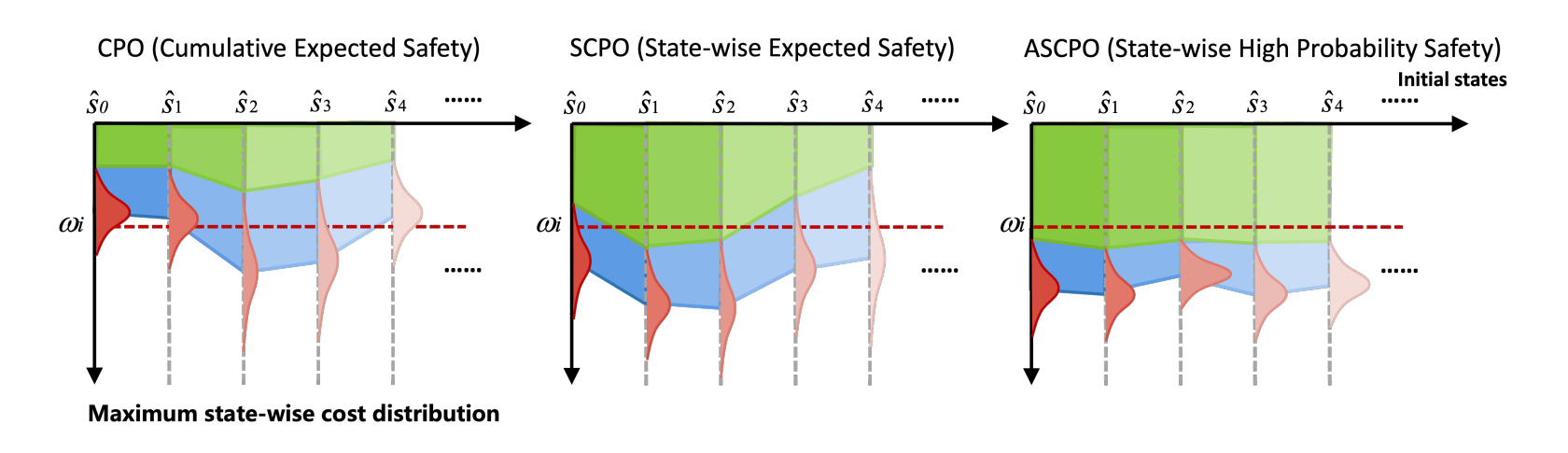
To achieve state-wise worst-case safety, we build upon our State-wise Constrained MDP (SCMDP) and Maximum MDP (MMDP) framework. We introduce the State-wise Constrained Policy Optimization (SCPO) algorithm to ensure state-wise expected safety satisfaction. Building on these results, we further develop the Absolute SCPO (ASCPO) algorithm to achieve satisfaction of state-wise worst-case safety with high probability.
Contributors: Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei, Yujie Yang
Contributors: Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei, Yujie Yang
Publications:
-
[J24] State-wise Constrained Policy Optimization
Weiye Zhao, Rui Chen, Yifan Sun, Tianhao Wei and Changliu Liu
Transactions on Machine Learning Research, 2024
-
[U] Absolute State-wise Constrained Policy Optimization: High-Probability State-wise Constraints Satisfaction
Weiye Zhao, Feihan Li, Yifan Sun, Yujie Wang, Rui Chen, Tianhao Wei and Changliu Liu
arXiv:2410.01212, 2024
Acquiring a Robust and Safe RL Policy Without Violations During Training
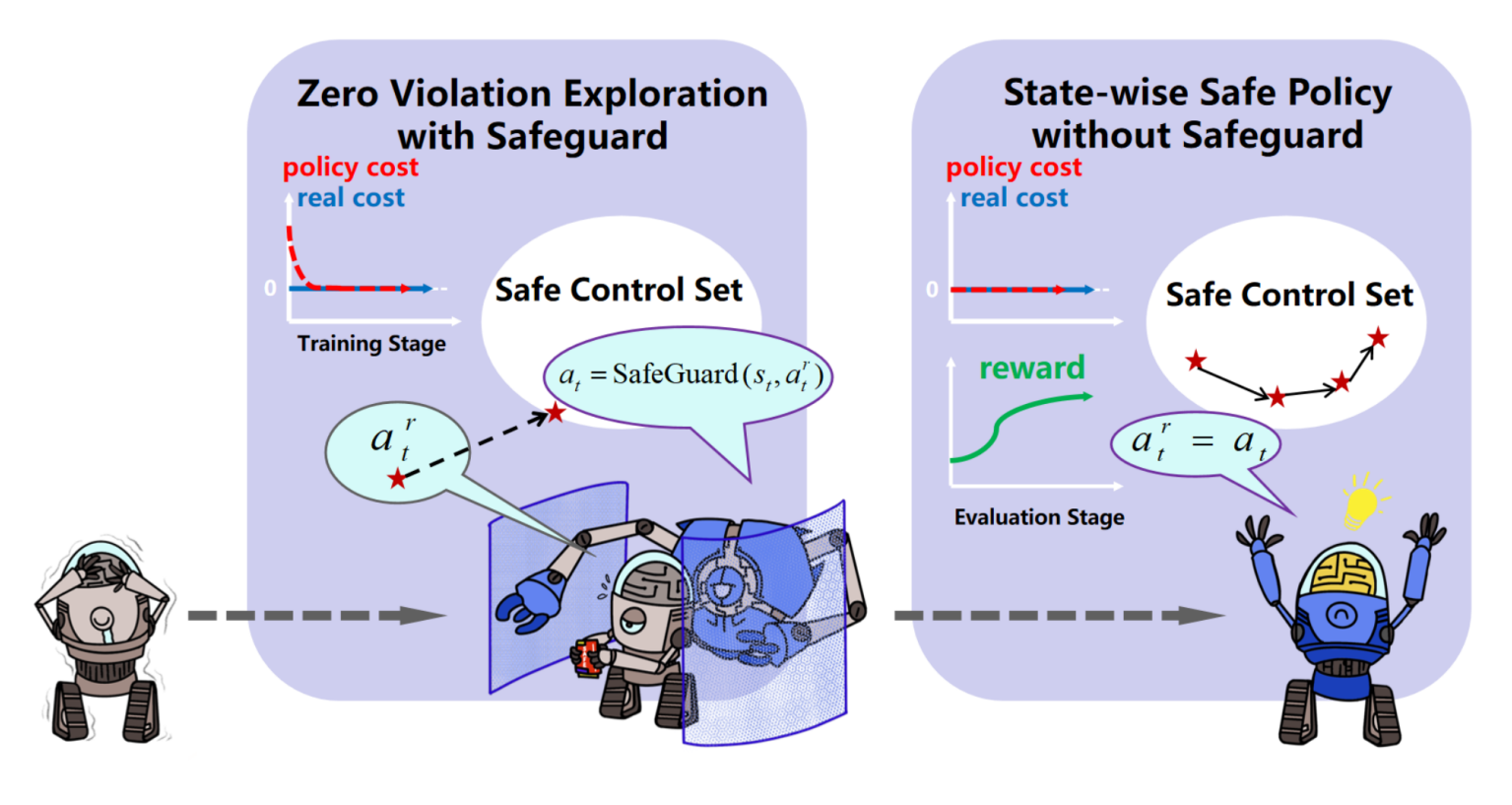
This work presents Safe Set Guided Statewise Constrained Policy Optimization (S-3PO), a deep reinforcement learning algorithm that ensures zero training violations while learning safe optimal policies. S-3PO uses a safety-oriented monitor for safe exploration and introduces an "imaginary" cost to guide the agent within safety constraints. It outperforms existing methods in high-dimensional robotics tasks, marking a significant step towards real-world safe RL deployment.
Contributors: Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Tianhao Wei
Contributors: Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Tianhao Wei
Publications:
Period of Performance: 2023 ~ Now
Point of Contact: Weiye Zhao